

Il Document Object Model è una parte fondamentale del World Wide Web. DOM in breve, questo è un insieme di standard API che definiscono come un browser deve costruire un documento web e come gli sviluppatori sono in grado di manipolare gli oggetti.
Daremo un ulteriore sguardo al funzionamento del DOM. Il modello esiste da anni e attualmente risiede al livello DOM 3 (documentazione DOM3 qui). C'è un DOM4 attualmente in bozza editoriale con alcune nuove specifiche in arrivo. Per ora possiamo concentrarci su una breve comprensione di come è nato il modello dell'oggetto.
Una lezione di storia
Durante i primi giorni di scripting web non c'era un modo standard per accedere agli oggetti della pagina. Ciò ha permesso ai principali browser di entrare e scrivere i propri standard e le regole per la manipolazione dei documenti. Le aziende di software hanno persino scritto i propri linguaggi di scripting come VBScript di Microsoft e Applescript di Apple.
I primi modelli erano molto limitati. È possibile accedere solo a elementi specifici come immagini o input di moduli. Nel tempo il World Wide Web Consortium ha sviluppato un modello standard seguito dalla maggior parte degli editori di software mainstream. In particolare Microsoft Internet Explorer, Netscape, Safari e Opera.
Attualmente il DOM ha attraversato molte revisioni e consente una manipolazione molto precisa degli elementi della pagina. Con librerie di script come jQuery e MooTools gli sviluppatori sono in grado di dedicare molto meno tempo ai bug.
Modern DOM Scripting Today
JavaScript è di gran lunga il linguaggio più popolare tra gli sviluppatori. Originariamente è stato avviato come progetto open source da Netscape nel 1995. Si basa sul popolare linguaggio di programmazione Java ed è stato modificato da innumerevoli comunità di sviluppatori web.
Il DOM stesso è utile solo nelle situazioni in cui è possibile accedere agli oggetti. Per la maggior parte, tutti i browser conformi agli standard oggi supportano tutti gli elementi e i metodi per la manipolazione DOM completamente. Con questa standardizzazione del modello a oggetti abbiamo assistito a un aumento delle funzionalità di scripting e di pagina semplici.
L'albero dei documenti
Quando si immagina il DOM, può essere facilmente compreso rispetto ad un albero. Quando un documento carica ogni elemento della pagina viene tenuto in memoria come un nuovo oggetto. Questi sono a volte indicati come nodi dell'albero
Ad esempio, ogni pagina HTML corretta dovrebbe iniziare con un elemento HTML e tutto il contenuto della pagina dovrebbe essere caricato all'interno di a corpo elemento. Ciò significa che la gerarchia dell'albero inizia da un elemento HTML radice e attraversa il suo primo nodo corpo.
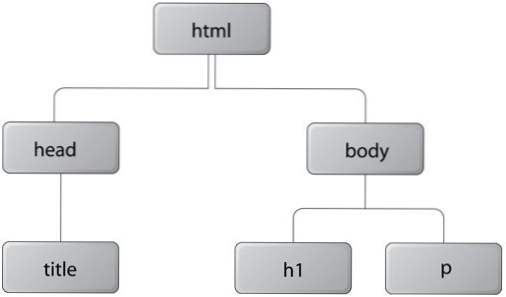
Questa è un'idea semplice ma fornisce immenso potere agli sviluppatori. Da questo siamo in grado di estrarre molti tipi di elementi dalla pagina semplicemente accedendo al loro specifico nodo o posizione nel documento. È possibile scrivere un piccolo script per estrarre tutte le immagini da una pagina e inserirle in una matrice per l'archiviazione.
Da qui è possibile accedere a ciascun elemento dell'immagine tramite JavaScript. Di seguito ho aggiunto un codice che imposta 2 variabili. Il primo tiene in memoria il terzo oggetto immagine mentre il secondo tira il src stringa dall'elemento.
Metodi di nodo
Una volta che hai la possibilità di manipolare e accedere ai nodi, sei in grado di spingere le funzioni su di essi. Il modello a oggetti non è solo per attraversare la pagina ma anche per applicare nuovi effetti.
Questi sono chiamati metodi e sono scritti nella specifica DOM. Quando si immagina un sistema ad albero basato sul nodo, questi metodi risolveranno qualsiasi confusione. Di seguito è riportato un breve elenco di alcuni metodi popolari che è possibile utilizzare sui nodi:
nodeA.firstChildnodeA.lastChildnodeA.parentNodenodeA.nextSiblingnodeA.prevSibling
La maggior parte di questi metodi può essere utilizzata all'interno di una dichiarazione di variabile o di una dichiarazione di ritorno di funzione. Restituiranno un oggetto dal DOM in relazione al posizionamento corrente.
I primi due prenderanno rispettivamente il primo nodo interno e l'ultimo nodo interno. Questo è ciò che la parola chiave bambino dovrebbe rappresentare, con NodoA essere il genitore di entrambi i bambini. Questo dovrebbe anche spiegare come parentNode funziona come puoi tirare l'oggetto nodo che si trova direttamente sopra il tuo attuale selettore.

Entrambe le funzioni di pari livello sono sconosciute alla maggior parte e gli elementi target allo stesso livello gerarchico. Ad esempio se stavi attraversando una lista non ordinata con 3 Li tag che potevi solo chiamare nextSibling 2 volte prima di tornare nullo. Molte di queste funzioni sono state ridimensionate da librerie di terze parti in metodi più rapidi e accurati.
Classi di elementi e ID
Uno dei modi più popolari per recuperare le informazioni sugli oggetti è attraverso il targeting diretto. Se hai scritto codice HTML, dovresti conoscere gli attributi di classe e ID. Questi possono essere impostati su qualsiasi elemento della pagina e sono notoriamente utili per applicare gli stili CSS.

Quando si creano questi attributi, il DOM li riconosce come ambienti separati dal documento generale. Gli ID devono essere unici tra la tua pagina e causano errori di scripting se si duplica lo stesso nome. Le classi possono contenere innumerevoli elementi, sebbene possano impantanarsi rapidamente.
Il metodo popolare getElementById () è stato utilizzato dagli sviluppatori per un decennio per semplificare il processo di manipolazione degli oggetti. Questo metodo accetta un singolo argomento di stringa che contiene il valore ID di qualsiasi elemento che stai cercando di targetizzare. Come tale puoi cambiare un'immagine src attribuire rapidamente con un codice simile:
Avanzamenti nel modello
Con il rilascio della famosa libreria jQuery è più facile che mai sviluppare potenti script. Funzioni precedenti come getElementById () e getElementsByTagName () sono ancora accessibili, sebbene deprecati dalla maggior parte degli standard.
Il modo più rapido per iniziare a manipolare il DOM è accedere agli oggetti tramite jQuery. Una semplice chiamata di metodo $ (Document) .ready ({}) è tutto ciò che è necessario per eseguire un nuovo evento. Il $() la sintassi viene utilizzata per rappresentare l'estrazione di qualsiasi tipo di oggetto dalla pagina.

Questo può essere usato all'unisono per estrarre ID e tag da una pagina. Ognuno richiede semplicemente gli stessi simboli utilizzati nelle dichiarazioni CSS come $ ( '# Myid') e $ ('. Myclass'). Una volta dentro la funzione ready jQuery ti consente di estrarre tutti gli eventi e le funzioni di cui hai bisogno.
La libreria è ottimizzata per la velocità e con il DOM che sta avanzando rapidamente stiamo assistendo a enormi salti nel supporto dello scripting. Ogni nodo viene caricato in uno slot di memoria oggetto che sia il browser Web e lo sviluppatore può accedere.
Conclusione
Il movimento open source ha largamente contribuito anche al progresso delle specifiche del DOM. Negli ultimi 10 anni abbiamo visto XML accolto nella documentazione insieme ai modi di definire i feed di contenuto (RSS, Atom, ecc.).
È importante rimanere aggiornati sulle tendenze come sviluppatore web. Il web sta avanzando rapidamente e le ultime revisioni del Document Object Model mostrano quanto controllo è disponibile oggi. Se desideri approfondire ulteriormente lo scripting DOM, ti offriamo raccolte di trucchi jQuery e molti tutorial video sul Web design completamente gratuiti!